昨天了解了一下如何用 GPT 来做问答知识库,比如 Supabase 的技术文档可以使用自然语言提问,然后由 AI 给出回答。
自己也动手做了一个小工具来做试验:用了 LangChain 框架,调用 OpenAI 的 GPT-3.5 Turbo 模型进行实现。Embedding 使用 text-embedding-ada-002-v2。
基本问题
OpenAI 的 API 简洁易懂,而且 LangChain 提供了抽象,事实上不需要关心 OpenAI 的 API 的用法,只需要关心 LangChain 具体函数 API。
要想构建知识库,则首先要搞清楚下面两个问题:
- 模型怎么能知道关于特定文档的知识?
- 对话历史记录如何保存?
解决了这两个问题,基本就搭建好了该聊天机器人的基本框架。
构建向量存储
考虑到我们要调用外部 API 来获得结果,因此每次解答来自用户的问题时,将所有文档作为输入是不现实的(即使没有 token 限制)。
而且 OpenAI 提供的 API 是无状态的,意味着它本身不会意识到之前的对话内容。
因此,我们需要通过其他方法在单次调用 API 的请求体中包含解答问题必要的上下文知识。
一种解决方案是根据文档生成 Embeddings,每一条 embedding 都是一个由若干浮点数组成的向量。因此可以计算向量之间距离,以代表相似程度。这些由文档生成的向量们可以被视为代表每个段落(chunk),当我们把用户的问题同样转换成向量时,我们可以通过计算和文档向量们的距离,来找到与之对应的最近(最相似)的一些段落。
当我们把这些段落作为背景信息发送给 OpenAI 的 API 时,模型即可以此来回答用户的问题。
LangChain 提供了 VectorstoreIndexCreator 可以根据文档创建一个向量的索引。
构建对话历史
一个简单的方式是将所有对话历史消息添加到 prompt 里,比如 LangChain 给出的示例:
1 | The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know. |
但随着对话进行,历史消息越来越多,最终会超出单次 API 调用的 token 限制。
一种解决方案是只保留最近 K 个对话消息,作为一部分,缺点是对过去对话信息的一些丢失。但最近 K 个消息中,可能也足以让模型推断出对话的背景。
另外一种解决方案是同时针对过去的对话让 LLM(大型语言模型,本例中即同样使用 OpenAI 的 GPT 3.5)进行总结,然后再作为 prompt 的一部分。这个总结将提供所需要的基本背景信息,至少让模型了解个大概。
LangChain 提供了 ConversationSummaryBufferMemory 来实现了「总结 + K 条对话」的逻辑,因此我们可以直接使用,而不必重复具体实现。
示意图
以下是上文所讨论的实现方式的具体示意图:
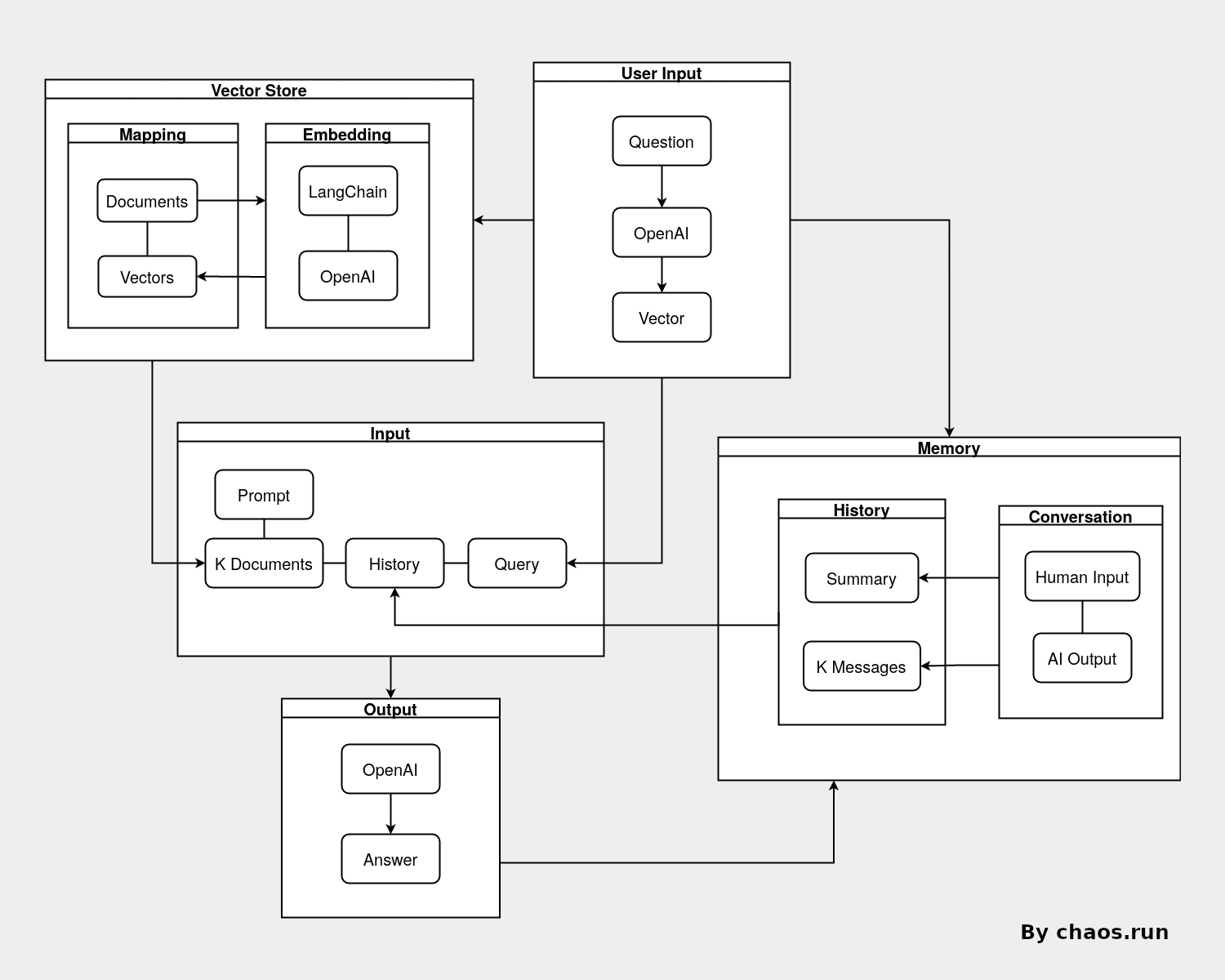
首先利用所有文档 + LangChain + OpenAI Embedding 来创建 Vector Store。
当接受到用户的问题后,再生成该问题的向量,以此向量得到 K 个最相似的文档段落,作为 prompt 关于背景信息的一部分。
同时在对话历史中获取最近的 K 条消息,以及对话的总结,作为 prompt 关于历史消息的一部分。
再将用户原始的消息作为 prompt 最终的问题,向 OpenAI 提供的模型提问,得到回答。
最后将该问题和回答记录,作为 Memory 存储的一部分。
代码及演示
仅作为实验用途,因此为了快速验证,使用了 Streamlit 作为网页应用框架。
使用了 PrCore 的文档作为待使用的知识库。
代码托管在 GitHub
演示网站位于 https://prcore-assistant.chaos.run
效果如下:

通过 Prompt 限定了模型只回答有关 PrCore 文档的问题。